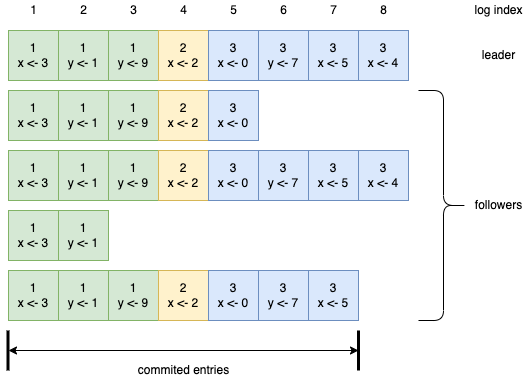
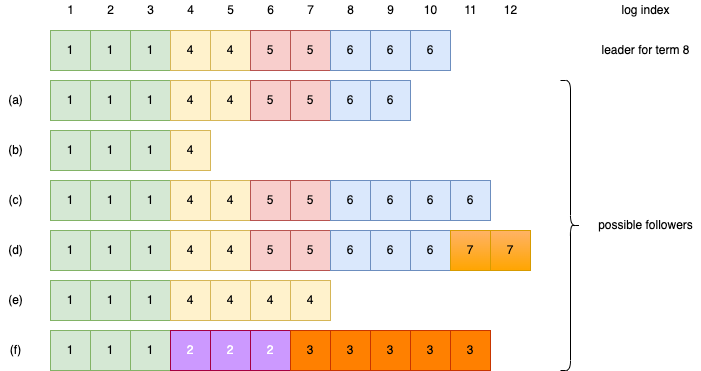
在上图中,方块中的数字表示任期。当前已提交的日志的索引位置是1-9,一共有四台机器在1-9位置的日志相同,符合过半数的原则。a 和 b 相比于主节点来说缺少日志,c 和 d 相比于主节点来说有多余的日志,e 和 f 两种情况都有。对于 f 来说,它在任期2中被选为主节点,然后开始接受客户端请求并写入本地日志,但是还没有成功复制到其他从节点上就异常了,恢复后又被选举为任期3的主节点,又重复了类似的操作。
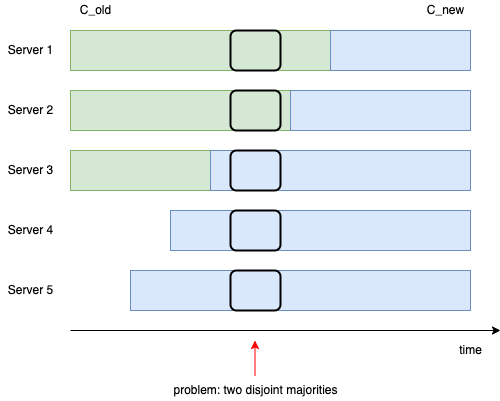
在上图中,集群由原来3台机器扩展为5台,由于每台服务器实际替换配置文件的时机不同,如红色箭头所示,存在某一时刻集群中可能会有两个主节点,假设此时发生选主,由于在 Server 1 看来集群中的节点数量还是3个,所以它只要获取到 Server 2 的选票就可以声明自己为主节点;而在 Server 5 看来,此时集群中有5个节点,所以它在获取了 Server 3、Server 4 的选票后就成为主节点,此时集群中就存在了两个主节点。
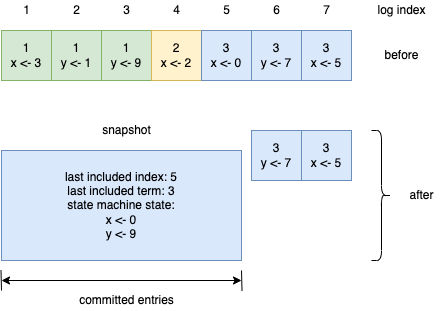
上图展示了 Raft 快照的概念。每台服务器会独立的执行快照,并且只包含已提交的日志。执行快照时大部分的工作是状态机将当前的状态写入到快照中。Raft 同时添加了一小部分元数据到快照中:快照对应的最后一个日志的索引(last included index,状态机已应用的最后一条日志),以及最后一个日志对应的任期(last included term)。这两个元数据信息用于执行快照后的第一次 AppendEntries 请求的一致性检查,因为需要比对前一个日志的索引和任期。同时为了启用集群配置变更,快照中也保存了当前最新的集群配置。一旦服务器完成了快照的写入,那么它就可以删除到快照为止的所有日志,以及以前的快照。
第二个性能问题是一次写快照可能会花费较长的时间,所以需要它不能延误正常操作。解决方法是使用写时复制技术(copy-on-write),这样节点也能同时接受新的更新而不会影响快照。例如,由函数式数据结构组成的状态机天然的支持写时复制。或者操作系统的写时复制支持(例如 Linux 的 fork)可以用来在内存中创建一份整个状态机的快照(Raft 的实现采用了这种方式)。
另一种只需要耗费少量带宽的方式是状态机(state machine)同步。该方法将主从同步抽象为确定性状态机(deterministic state machine)同步问题,在确定性状态机模型下,对于两个初始状态一样的状态机来说,按照相同的顺序执行相同的一系列输入指令后,最后的状态也一定是相同的。然而,对于大部分的服务来说,存在某些非确定性的操作,例如生成一个随机数,这时候就需要额外的协调使得主从间依然是同步的,即从节点也要生成一模一样的随机数。不过,处理这种情况所需要维护的额外信息相比于主节点状态的修改(主要是内存的修改)来说不值一提。
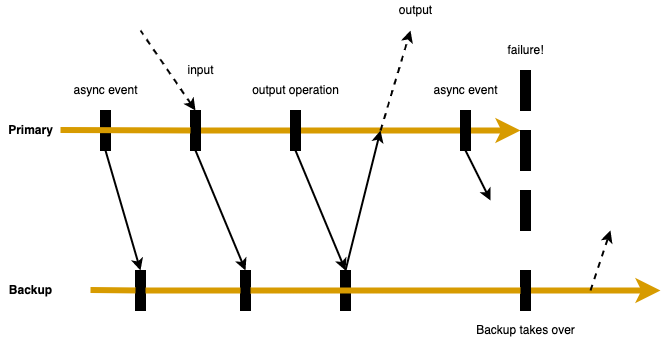
通过主虚拟机的延迟输出,保证从虚拟机确认收到了所有日志后,主虚拟机才将输出返回给客户端来实现 Output Requirement。一个先决的条件是主虚拟机在执行输出操作前,从虚拟机必须已经收到所有的日志。这些日志能保证从虚拟机执行到主虚拟机最新的执行点。然而,假设当主虚拟机刚开始执行输出操作时发生了异常,此时发生了主从切换,从虚拟机必须先将未处理完的日志进行重放,然后才能 go live(不再执行重放,接管成为主虚拟机)。如果在这之前从虚拟机 go live,可能会有一些非确定性的事件(例如计时器中断)在从虚拟机执行输出操作前改变了执行的路径。
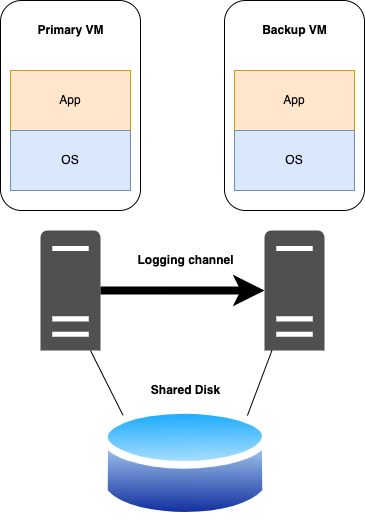
上图展示了 FT 协议的要求。主虚拟机到从虚拟机的箭头表示日志的发送,从虚拟机到主虚拟机的箭头表示日志的确认。所有异步事件,输入和输出的操作都必须发送给从虚拟机并得到确认。只有当从虚拟机确认了某条输出操作的日志后,主虚拟机才能执行输出操作。所以只要遵循了 Output Rule,从虚拟机在接管执行时就能保持和主虚拟机一致的状态。
不过在异常发生时,VMware FT 并不能保证所有的输出只发送一次。在缺少两阶段提交的帮助下,从虚拟机不能知晓主虚拟机在发送某条输出之前还是之后发生了异常。不过,网络协议(包括常见的 TCP 协议)在设计时就已经考虑了包的丢失和重复包的情况,所以这里无需特殊处理。另外,在主虚拟机异常时发送给主虚拟机的输入也有可能丢失,因此从虚拟机也会丢失这部分的输入。不过,即使在主虚拟机没有异常的情况下,网络包本身就有可能丢失,所以这里同样也不需要特殊处理,不管是网络协议、操作系统还是应用程序,在设计和编写时本身已经考虑到了包丢失的情况。
监测和响应异常
之前提到过,当主虚拟机或者从虚拟机发生异常时,双方都必须能快速响应。当从虚拟机异常时,主虚拟机会进入 go live 模式,即不再记录执行日志,以常规的方式执行。当主虚拟机异常时,从虚拟机也会进入 go live 模式,不过相比于主虚拟机略微复杂些。因为从虚拟机在执行上本身就落后于主虚拟机,在主虚拟机异常时,从虚拟机已经收到和确认了一部分执行日志,但是还没有执行重放,此时从虚拟机的状态和主虚拟机还是不一致的。所以,从虚拟机必须先将暂存的日志进行重放,当所有重放都执行完成后,从虚拟机就会进行 go live 模式,正式接管主虚拟机(此时缺少一个从虚拟机)。因为此时这台从虚拟机不再是从虚拟机,被虚拟化的操作系统所执行的输出操作都会发送给客户端。在这个转换期间,可能也需要某些设备执行一些特定的操作来保证后续输出的正确性。特别是对于网络输出来说,VMware FT 会自动的将新的主虚拟机的 MAC 地址在网络中广播,使得物理交换机知道最新的主虚拟机的地址。另外,后文会提到新的主虚拟机可能会重新发起一些磁盘 IO 操作。
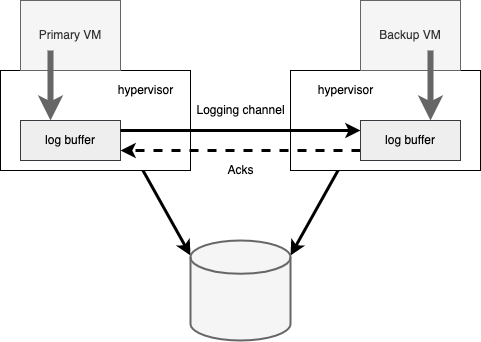
有很多种方式来监测主虚拟机和从虚拟机的异常。VMware FT 通过 UDP 心跳来监测启用了容错的虚拟机是否发生了异常。另外,VMware FT 还会监控 logging channel 中的流量,包括主虚拟机发送给从虚拟机的日志,以及从虚拟机的消息确认回执。因为操作系统本身存在时钟中断,所以理论上来说 logging channel 中的流量应该是连续不断的。因此,如果监测到 logging channel 中没有流量了,那么就可以推断出某台虚拟机发生了异常。如果没有心跳或者 logging channel 中没有流量超过一段指定的时间(近似几秒钟),那么系统就会声明这台虚拟机发生了异常。
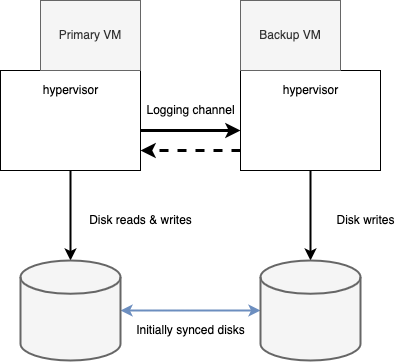
然而,这种异常监测机制可能会引发脑裂问题。如果从虚拟机不再接收到来自主虚拟机的心跳,那么有可能说明主虚拟机发生了异常,但也有可能只是双方间的网络断开。如果此时从虚拟机进入 go live 模式,由于此时主虚拟机依然存活,就有可能给客户端造成数据损坏或其他问题。因此,当监测到异常时必须保证只有一台主虚拟机或者从虚拟机进入 go live 模式。为了解决脑裂问题,VMware FT 借助了虚拟机所连接的共享存储。当主虚拟机或者从虚拟机希望进入 go live 模式时,它会向共享存储发起一个原子性的 test-and-set 操作。如果操作成功,那么当前虚拟机可以进入 go live 模式,如果操作失败,说明已经有其他虚拟机先进入了 go live 模式,所以当前虚拟机就将自己挂起。如果虚拟机访问共享存储失败,那么它会一直等待直到访问成功。如果共享存储由于网络问题造成无法访问,那么虚拟机本身也做不了什么因为它的虚拟磁盘就挂载在共享存储上。所以使用共享存储来解决脑裂问题不会带来其他可用性问题。
最后一个设计的点是如果虚拟机发生了异常,使得某台虚拟机进入了 go live 模式,那么 VMware FT 会自动在其他物理机上启动一台新的备份虚拟机。
FT 的实际实现
上节主要描述了 FT 的基础设计和协议。然而,为了构建一个可用,健壮和自动化的系统,还需要设计和实现很多其他的组件。
其中一个原因造成主虚拟机的日志缓冲区写满是因为从虚拟机执行的太慢从而造成消费日志太慢。一般来说,从虚拟机必须以和主虚拟机记录执行日志一样的速度来执行重放。幸运的是,在 VMware FT 的实现下,记录执行日志和重放所需要的时间基本是相同的。不过,如果从虚拟机所在的机器存在和其他虚拟机资源竞争(资源超卖),不管 hypervisor 的虚拟机调度多么高效,从虚拟机都有可能得不到足够的 CPU 和内存资源来保证和主虚拟机一样的速度执行重放。
除了主虚拟机日志缓冲区满造成的不可控暂停外,还有一个原因也要求主从虚拟机间的状态不能差太远。当主虚拟机异常时,从虚拟机必须尽快的将所有的执行日志进行重放,达到和主虚拟机一样的状态,然后接管主虚拟机向客户端提供服务。结束重放的时间基本上等于异常发生时从虚拟机落后主虚拟机的时间,所以从虚拟机进入 go live 模式需要的时间就基本上等于检测出异常的时间加上当前从虚拟机落后的时间。因此,从虚拟机不能落后主虚拟机太多(大于一秒),否则这会大大增加故障切换的时间。
因此,VMware FT 有另一套机制来保证从虚拟机不会落后主虚拟机太多。在主从虚拟机间的通信协议里,还会发送额外的信息来计算两者间的执行时间差。一般来说这个时间差在100毫秒以内。如果从虚拟机开始明显落后主虚拟机(例如大于1秒),那么 VMware FT 会通知调度器降低主虚拟机的 CPU 资源配额(初始减少几个百分点)来延缓主虚拟机的执行。VMware FT 会根据从虚拟机返回的落后时间来不断调整主虚拟机的 CPU 资源配额,如果从虚拟机一直落后,那么 VMware FT 会逐渐减少主虚拟机的 CPU 资源配额。相反的,如果从虚拟机开始赶上了主虚拟机的执行速度,那么 VMware FT 会逐渐增加主虚拟机的 CPU 资源配额,直到两者的执行时间差到达一个合理的值。
不过在实际场景中减慢主虚拟机执行的速度非常少见,一般只会发生在系统承受极大负载的情况下。
FT 虚拟机上的操作
另一个实际中要考虑的问题是处理针对主虚拟机的一系列控制操作。例如,如果主虚拟机主动关机了,从虚拟机也需要同步关机,而不是进入 go live 模式。另外,所有对主虚拟机的资源修改(例如增加 CPU 资源配额)都必须应用到从虚拟机上。针对这些操作,系统会将其转化为特殊的执行日志发送到 logging channel,从虚拟机收到后也会将其正确的重放。
一般来说,大部分对虚拟机的操作都只应该在主虚拟机上发起。然后 VMware FT 会将其转化为日志发送给从虚拟机来进行重放。唯一可以独立的在主虚拟机和从虚拟机上执行的操作是 VMotion。即主虚拟机和从虚拟机都可以独立的被复制到其他机器上。VMware FT 保证了在复制虚拟机时不会将其复制到一台已经运行了其他虚拟机的机器上,因为这无法提供有效的容错保证。
在非共享磁盘的场景下,系统就不能借助共享存储来解决脑裂问题。在这种场景下,系统可借助其他的外部组件,例如某个主从虚拟机都可以连接的第三方服务器。如果主从服务器属于某个多于两个节点的集群,那么就可以使用某个选举算法来选择谁能进入 go live 模式。在这种场景下,如果某台虚拟机获得了大多数节点的投票,那么它就可以进入 go live 模式。
Posted onWord count in article: 23kReading time ≈38 mins.
介绍
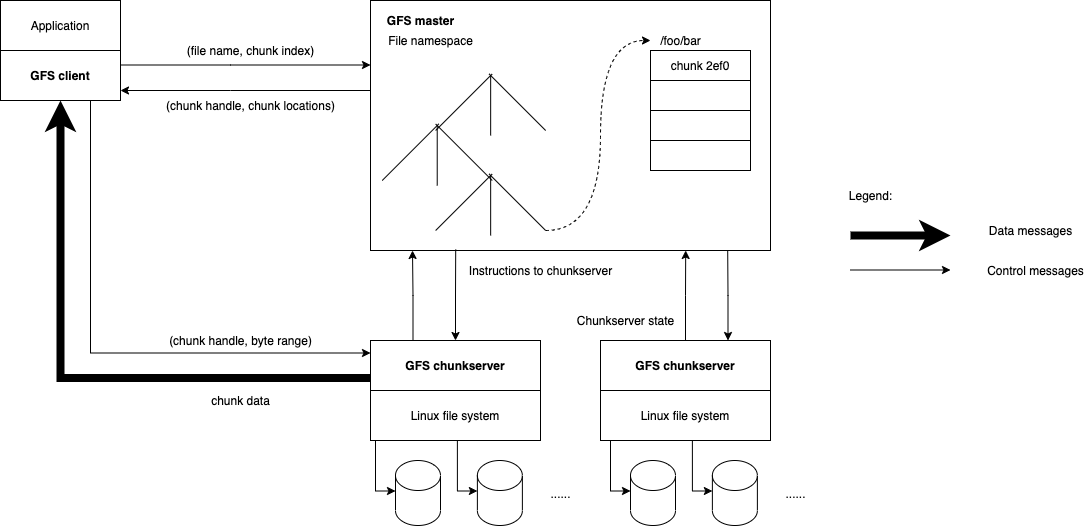
在 MapReduce: Simplified Data Processing on Large Clusters 中提到,MapReduce 任务的输入输出构建在 GFS 之上,GFS 是 Google 内部开发的一个分布式文件系统,用于应对大型的数据密集型应用。在 GFS 之前,业界已经存在了一些分布式文件系统的实现,为什么 Google 还要再实现一套?因为基于 Google 内部应用的特点,有别于传统的分布式文件系统,除了考虑性能、可扩展性、可靠性和可用性之外,GFS 在设计时还考虑了以下三个方面:
当主节点崩溃重启后会通过重放操作日志来恢复崩溃前的状态,然而如果每次都从第一条日志开始重放,主节点崩溃重启到可用需要的时间会越来越久,因此当操作日志的大小增长到一定程度的时候,主节点会为当前的元数据创建一个检查点,当主节点崩溃恢复后,可以先加载最新的检查点数据,然后再重放在这个检查点之后生成的操作日志。检查点是一个类似于 B 树的数据结构,可以轻易的映射到内存数据结构中,并且方便根据文件的命名空间检索。这就加快了主节点崩溃恢复的速度和提高了系统的可用性。
追加写在 Google 的分布式应用中使用的非常频繁,多个客户端会并发的对同一个文件追加写入。在传统的随机写操作下,客户端需要额外的同步机制例如实现一个分布式锁来保证写入的线程安全性。在 Google 的应用场景下,文件一般是作为一个多生产者/单消费者的缓冲队列或者包含了多客户端合并后的结果,所以追加写已经能满足需求。
mrworker.go 中注释描述通过 go run mrworker.go wc.so 来运行工作节点,不过如果构建 wc.so 时开启了竞争检测(-race),则运行 mrworker.go 时也同样需要开启竞争检测,否则会提示 cannot load plugin wc.so,如果打印 err 则会显示 plugin.Open("wc"): plugin was built with a different version of package runtime。
// // The map function is called once for each file of input. The first // argument is the name of the input file, and the second is the // file's complete contents. You should ignore the input file name, // and look only at the contents argument. The return value is a slice // of key/value pairs. // funcMap(filename string, contents string) []mr.KeyValue { // function to detect word separators. ff := func(r rune)bool { return !unicode.IsLetter(r) }
// split contents into an array of words. words := strings.FieldsFunc(contents, ff)
kva := []mr.KeyValue{} for _, w := range words { kv := mr.KeyValue{w, "1"} kva = append(kva, kv) } return kva }
reduce 函数的输出类型为 string,其逻辑较为简单,中间结果数组的长度就是单词的个数:
1 2 3 4 5 6 7 8 9
// // The reduce function is called once for each key generated by the // map tasks, with a list of all the values created for that key by // any map task. // funcReduce(key string, values []string)string { // return the number of occurrences of this word. return strconv.Itoa(len(values)) }
框架代码
我们可以通过 go run -race mrsequential.go wc.so pg*.txt 来运行串行化的 MapReduce 程序,这里的 wc.so 内包含了用户自定义的 map 和 reduce 函数,pg*.txt 则是本次 MapReduce 程序的原始输入数据。
首先,根据入参提供的插件找到用户自定义的 map 和 reduce 函数:
1
mapf, reducef := loadPlugin(os.Args[1])
接着,依次读取输入文件的内容,并调用用户自定义的 map 函数,生成一组中间结果数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
// // read each input file, // pass it to Map, // accumulate the intermediate Map output. // intermediate := []mr.KeyValue{} for _, filename := range os.Args[2:] { file, err := os.Open(filename) if err != nil { log.Fatalf("cannot open %v", filename) } content, err := ioutil.ReadAll(file) if err != nil { log.Fatalf("cannot read %v", filename) } file.Close() kva := mapf(filename, string(content)) intermediate = append(intermediate, kva...) }
// // a big difference from real MapReduce is that all the // intermediate data is in one place, intermediate[], // rather than being partitioned into NxM buckets. //
// // call Reduce on each distinct key in intermediate[], // and print the result to mr-out-0. // i := 0 for i < len(intermediate) { j := i + 1 for j < len(intermediate) && intermediate[j].Key == intermediate[i].Key { j++ } values := []string{} for k := i; k < j; k++ { values = append(values, intermediate[k].Value) } output := reducef(intermediate[i].Key, values)
// this is the correct format for each line of Reduce output. fmt.Fprintf(ofile, "%v %v\n", intermediate[i].Key, output)
Hello, world ================== WARNING: DATA RACE Write at 0x00c00007e180 by goroutine 7: runtime.mapassign_faststr() /usr/local/go/src/runtime/map_faststr.go:203 +0x0 main.main.func1() /path/to/racy.go:10 +0x50
Previous read at 0x00c00007e180 by main goroutine: runtime.mapaccess1_faststr() /usr/local/go/src/runtime/map_faststr.go:13 +0x0 main.main() /path/to/racy.go:13 +0x16b
Goroutine 7 (running) created at: main.main() /path/to/racy.go:9 +0x14e ================== ================== WARNING: DATA RACE Write at 0x00c000114088 by goroutine 7: main.main.func1() /path/to/racy.go:10 +0x5c
Previous read at 0x00c000114088 by main goroutine: main.main() /path/to/racy.go:13 +0x175
Goroutine 7 (running) created at: main.main() /path/to/racy.go:9 +0x14e ================== Found 2 data race(s) exit status 66
这个例子中每次循环时会创建一个 goroutine,每个 goroutine 会打印循环计数器 i 的值:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
package main
import ( "fmt" "sync" )
funcmain() { var wg sync.WaitGroup wg.Add(5) for i := 0; i < 5; i++ { gofunc() { fmt.Println(i) // Not the 'i' you are looking for. wg.Done() }() } wg.Wait() }
我们想要的结果是能输出 01234 这5个值(实际顺序并不一定是 01234),但由于主 goroutine 对 i 的更新和被创建的 goroutine 对 i 的读取之间存在数据竞争,最终的输出结果可能是 55555 也可能是其他值。
如果要修复这个问题,每次创建 goroutine 时复制一份 i 再传给 goroutine 即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
package main
import ( "fmt" "sync" )
funcmain() { var wg sync.WaitGroup wg.Add(5) for i := 0; i < 5; i++ { gofunc(j int) { fmt.Println(j) // Good. Read local copy of the loop counter. wg.Done() }(i) } wg.Wait() }
// ParallelWrite writes data to file1 and file2, returns the errors. funcParallelWrite(data []byte)chanerror { res := make(chanerror, 2) f1, err := os.Create("file1") if err != nil { res <- err } else { gofunc() { // This err is shared with the main goroutine, // so the write races with the write below. _, err = f1.Write(data) res <- err f1.Close() }() } f2, err := os.Create("file2") // The second conflicting write to err. if err != nil { res <- err } else { gofunc() { _, err = f2.Write(data) res <- err f2.Close() }() } return res }
// ParallelWrite writes data to file1 and file2, returns the errors. funcParallelWrite(data []byte)chanerror { res := make(chanerror, 2) f1, err := os.Create("file1") if err != nil { res <- err } else { gofunc() { // This err is shared with the main goroutine, // so the write races with the write below. _, err := f1.Write(data) res <- err f1.Close() }() } f2, err := os.Create("file2") // The second conflicting write to err. if err != nil { res <- err } else { gofunc() { _, err := f2.Write(data) res <- err f2.Close() }() } return res }
funcmain() { c := make(chanstruct{}) // or buffered channel
// The race detector cannot derive the happens before relation // for the following send and close operations. These two operations // are unsynchronized and happen concurrently. gofunc() { c <- struct{}{} }() close(c) }
所以在关闭 channel 前,增加对 channel 的读取操作来保证数据发送完成:
1 2 3 4 5 6 7 8 9
package main
funcmain() { c := make(chanstruct{}) // or buffered channel