MIT 6.824 - Lab 2 (3): 实现
准备工作
日志
Debugging by Pretty Printing 中介绍了如何高效的打印日志,这有助于在实验时进行问题排查。
首先在 Go 侧需要封装一个日志打印函数 PrettyDebug(raft 目录下已经有了 Debug 变量,所以这里重命名为 PrettyDebug),在 raft 目录下新建一个 Go 文件,复制以下内容:
1 | package raft |
PrettyDebug 会通过环境变量 VERBOSE 来决定是否打印日志,该方法接受三个参数,第一个是日志主题用于对日志分组,后两个参数则是传递给 log.Printf 进行格式化打印,使用方法如下:
1 | PrettyDebug(dTimer, "S%d, apply log, log index=%v, log term=%v, log command=%v", rf.me, entry.Index, entry.Term, entry.Command) |
日志信息中的 S%d 是关键,它表示当前节点的编号,如 S0,S1,按照这个模式打印日志,在后续日志处理时能将日志按照节点分组。
然后,就可以通过 VERBOSE=1 go test -run TestFigure82C 来进行测试(这里的 TestFigure82C 可以换成其他的测试用例):
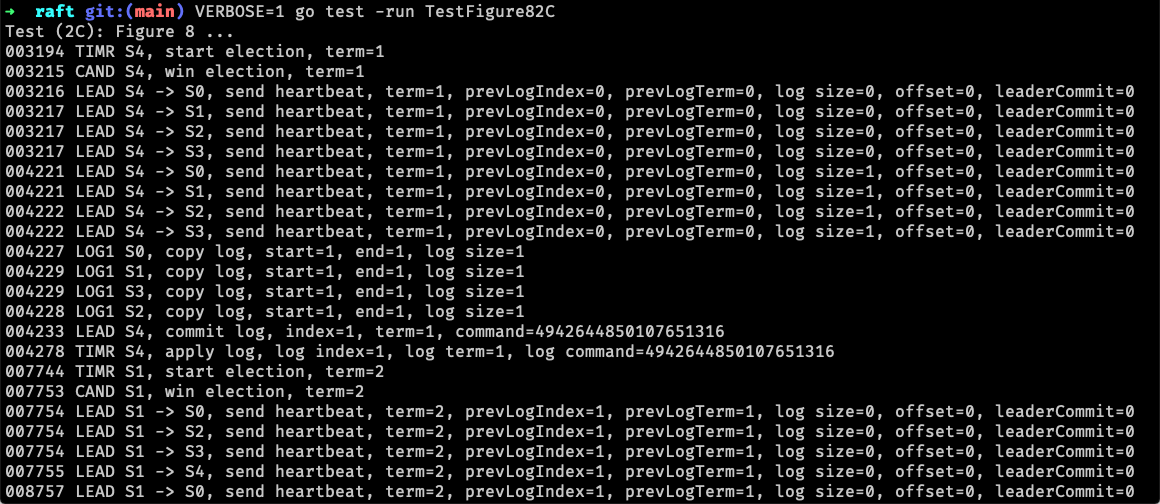
不过所有日志都混到了一起,不好区分,作者因此提供了一个 Python 脚本 dslogs 来美化日志。这个脚本用到了 typer 和 rich 两个库,可以通过 pip 全局安装。接着再执行测试 VERBOSE=1 go test -run TestFigure82C | pipenv run python dslogs.py(这里使用了 pipenv 来安装依赖和运行脚本,不使用 pipenv 的可以按照作者的方式执行),美化后的日志根据主题着色后有了更强的区分度:
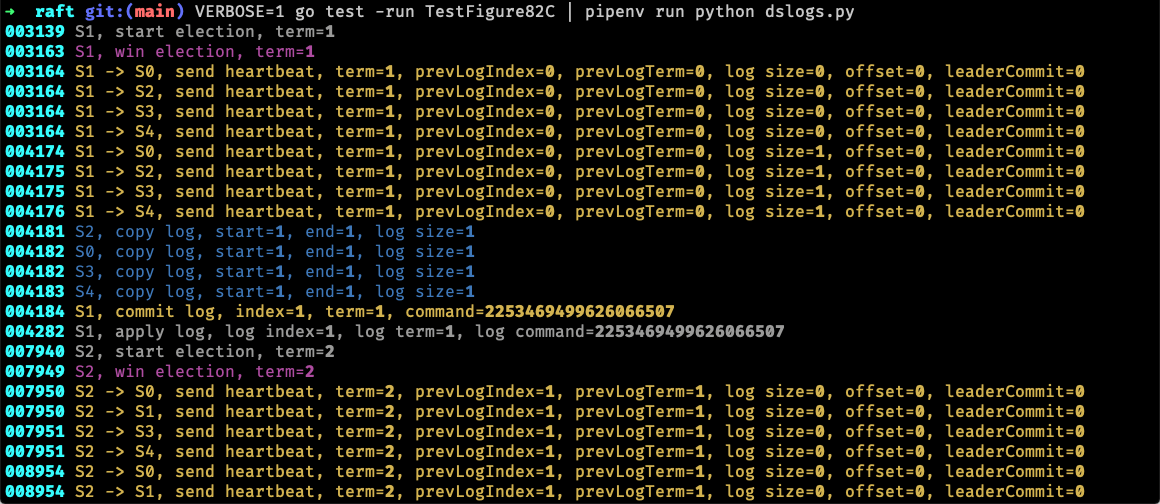
更进一步,还可以将日志按照节点分组展示 VERBOSE=1 go test -run TestFigure82C | pipenv run python dslogs.py -c 3:
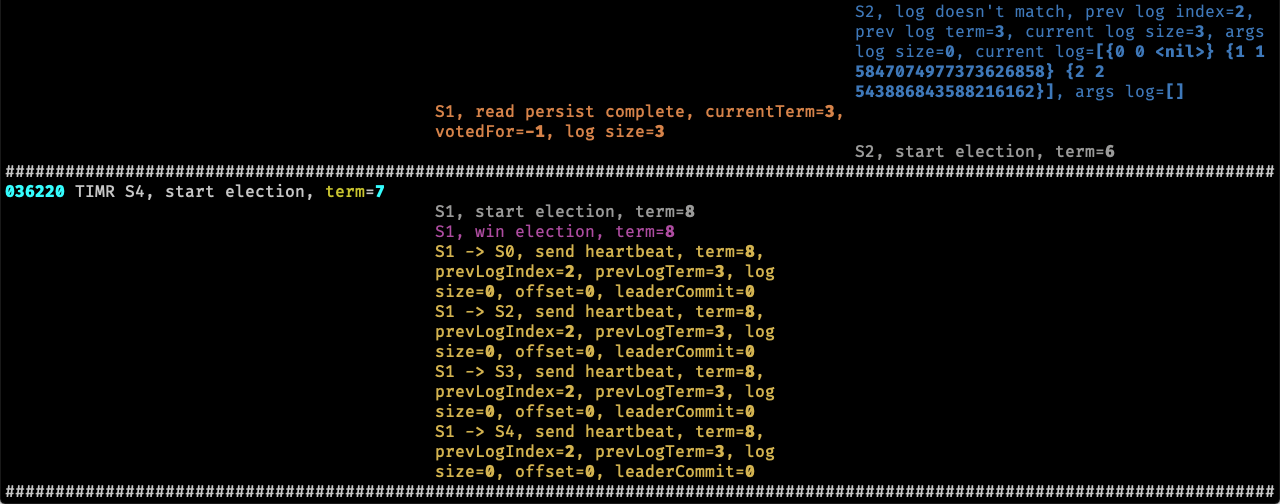
在上图中,每一列表示一个节点的日志,而且自上而下随时间排序。
批量测试
做实验时有时候测试用例成功了,有时候失败了,每次手动测试不方便抓取日志,Debugging by Pretty Printing 的作者提供了另一个脚本 dstest 来进行批量测试,并且当测试失败时自动保存日志到文件中,从而可以使用上面提到的脚本 dslogs 来处理日志,dstest 这个脚本也依赖 typer 和 rich 这两个库。
然后通过 pipenv run python dstest.py 2A -n 10 -v 1 进行批量测试,这里 2A 可以换成其他的测试用例,-n 10 表示测试多少次,默认是10,-v 1 表示设置环境变量 VERBOSE,这样就能告诉 Go 打印日志:
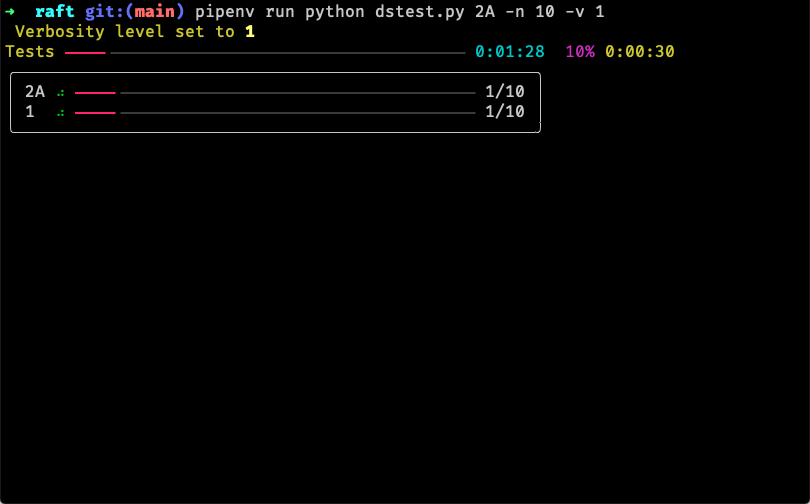
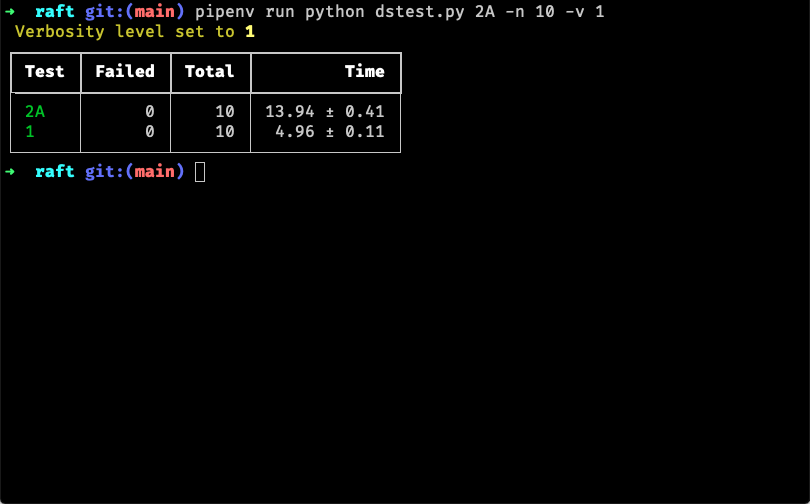
脚本貌似有个小问题,当设置 -v x 参数时,会多一个名为 x 的测试任务,不过并不影响使用。
如果某次测试执行失败,则会保存相应的日志:
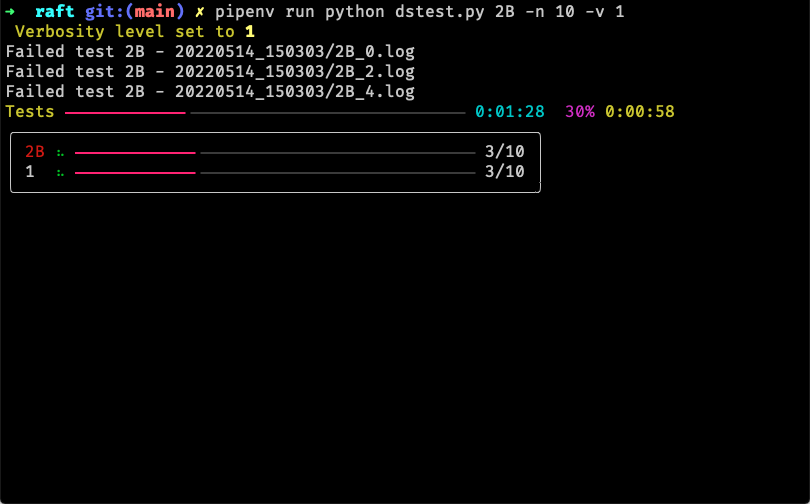
实现
2A
第一个实验是选主,关键有两点:随机化的 election timeout 和什么时候重置 election timeout。
当候选节点发出 RequestVote 请求后,应该在哪里判断是否获得了足够的选票?一种是在遍历完所有从节点发出 RequestVote 请求后,不过由于 RPC 的异步性,需要某种异步通知机制来通知当前的 goroutine。可以使用 sync.WaitGroup,事先计算好需要多少张选票才能成为主节点,发送 RPC 请求前调用 WaitGroup.Add(1),每当获得一张选票后就调用 WaitGroup.Done(),当获得了足够的选票后当前 goroutine 就能被唤醒,不过由于当前节点不一定能成为主节点,所以存在无法被唤醒的可能。虽然可以把 WaitGroup 设置成所有 RPC 都响应后再唤醒,不过整个响应时间就受限于最慢的 RPC 请求,等待时间可能会超过一个 election timeout 周期。使用这种方式的一个很大的问题就是无法及时响应其他候选节点成为主节点的情况,因为当前候选节点还阻塞在 WaitGroup.Wait()。
所以可以将是否获得了足够的选票的判断放在每个 RequestVote 的响应中。先初始化需要的选票数量,每次获得选票后使用原子方法 atomic.AddInt32 对票数减1,当返回票数小于等于0时,说明当前候选节点成为了主节点。
2B
第二个实验需要实现日志复制。日志是 Raft 的核心部分,首先定义 LogEntry,包含三个字段,索引、任期、指令:
1 | type LogEntry struct { |
之所以这里需要 Index 是因为需要对日志压缩,所以不能使用 rf.log 的数组下标作为日志项的索引。
复制日志时,可以选择在调用 Start 方法时就发送 AppendEntries 请求,并且在响应中判断从节点的日志是否匹配来更新 prevLogIndex,然后继续发送 AppendEntries 请求。不过,这会造成两个问题。
第一个问题是冗余的 RPC 请求,假设客户端连续调用了10次 Start,那么根据当前的 prevLogIndex 计算,主节点所发送的 AppendEntries 请求中分别包含1条日志,2条日志,…,10条日志。然而这10次 AppendEntries 请求完全可以由第10条请求替代,而如果 prevLogIndex 不匹配,主从节点间来回协调的过程又会带来更多的 RPC 交互,最终有可能导致测试用例 TestCount2B 的失败。
第二个问题是测试用例会模拟出特别不稳定的网络,如果在 AppendEntries 的响应中接着递归异步调用 AppendEntries,由于 goroutine 都在等待网络可能会造成同时存在的 goroutine 数量过多,导致测试失败。
所以,可以选择不在 Start 中发送带日志的 AppendEntries 请求,而是在常规心跳中根据 nextIndex 计算是否要发送日志。
2C
第三个实验是持久化,虽然从代码编写角度来说是所有实验中最简单和直白的,但是测试用例并不会比其他实验简单。特别是 TestFigure8Unreliable2C,容易在指定时间内无法提交某条日志,一方面是可以批量发送日志而不是逐条发送,另一方面是及时识别过期的 RPC 请求并丢弃,例如如果响应中的任期小于当前任期则可以直接忽略该响应,因为从节点收到请求时会更新任期(如果从节点的任期比主节点的小),并将更新后的任期放到响应中,所以在当前任期下主节点收到的响应中的任期必然等于当前任期,如果收到了小于当前任期的响应,必然是过期的响应。
2D
由于执行快照后会对日志压缩,所以 LogEntry.Index 和 rf.log 的数组索引不再一一对应,有两点需要改动,一是使用 len(rf.log) 表示日志长度的地方需要改为 rf.log[len(rf.log)-1].Index;二是使用 rf.log[i] 来引用 LogEntry 的地方需要将 i 减去某个偏移量,这个偏移量可以使用 lastIncludedIndex,例如,从节点想要判断 args.PrevLogIndex 所指向的日志的任期是否和主节点相同,需要改为 rf.log[args.PrevLogIndex-rf.lastIncludedIndex].Term 访问,因此 rf.lastIncludedIndex 也需要持久化。
另外还遇到两个死锁问题。第一个死锁发生在应用已提交的日志,日志的应用会由一个单独的 goroutine 执行,它会遍历所有需要应用的日志,然后发送到 applyCh,并且在整个期间持有锁:
1 | func (rf *Raft) applyLog(applyCh chan ApplyMsg) { |
这种处理方式在之前的实验中没有问题,不过在 2D 中,客户端从 applyCh 中取出数据后,有一定概率会调用 Snapshot 方法,而实现 Snapshot 方法时会继续获取锁,从而造成死锁:
1 | if (m.CommandIndex+1)%SnapShotInterval == 0 { |
这个问题也在 Raft Locking Advice 中提到,不建议在等待某个事件时持有锁。
第二个死锁发生在 InstallSnapshot,从节点收到快照后也会通过 applyCh 将快照发送给客户端,这里将 applyCh 作为 Raft 的一个字段使用,不过由于忘记赋值造成 InstallSnapshot 往一个空 channel 中发数据,造成始终阻塞,并导致死锁。
其他工具
go-deadlock
如果怀疑有死锁,可以使用 go-deadlock 检测,只需要将 Raft 中的 sync.Mutex 替换成 deadlock.Mutex 即可,如果某个 goroutine 在较长的一段时间后依然无法获取锁,那么就有可能发生了死锁,go-deadlock 会输出持有锁的 goroutine 和希望获取锁的 goroutine,而且也会输出持有锁的 goroutine 阻塞在哪个代码上:
1 | POTENTIAL DEADLOCK: |
pprof
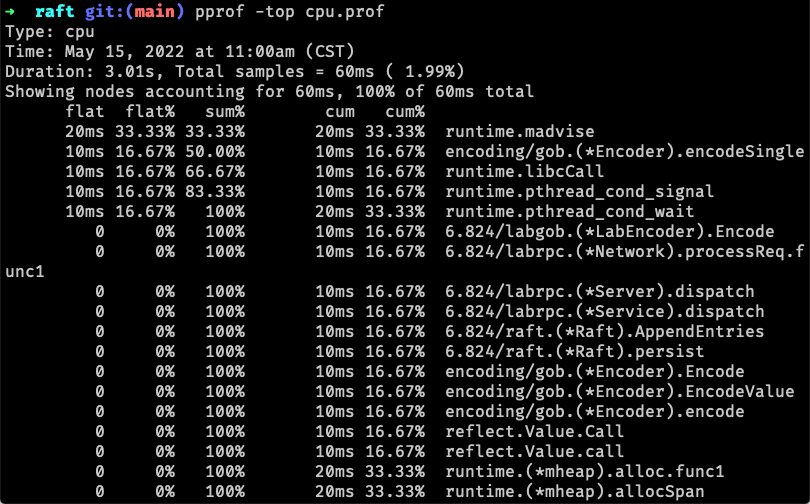
6.824 Lab 2: Raft 的每个实验都给出了参考的执行时间,如果发现某个实验的执行时间相差太大,可以使用 pprof 分析。这里以 CPU 耗时分析为例,首先在测试时增加 -cpuprofile cpu.prof 参数,其中 cpu.prof 是输出文件名:
1 | go test -run TestInitialElection2A -cpuprofile cpu.prof |
然后安装 pprof 并执行 pprof -top cpu.prof 分析: