【读】Bitcask - A Log-Structured Hash Table for Fast Key/Value Data
介绍
Bitcask 是一个单机 KV 存储引擎,项目起因于 Riak 分布式 KV 数据库需要一个能满足以下条件的单机 KV 存储引擎:
- 低延迟的单条读写
- 高吞吐,尤其是面对流式随机
KV写入 - 能支持远比内存大的数据量
- 能从崩溃中快速恢复以及不丢失数据
- 能轻松的备份和还原数据
- 相对简单,易理解的代码结构和数据格式
- 在高负载和大数据场景下系统的行为是可预期的
- 软件的许可证要能轻易的适配
Riak使用
作者看了一圈发现市面上还没有一款 KV 存储能全部满足这些条件,因此 Bitcask 就应运而生。
API
Bitcask 的接口非常精简:
| 接口 | 描述 |
|---|---|
| bitcask:open(DirectoryName, Opts) -> BitCaskHandle | {error, any()} | 在指定目录下以指定选项打开或新建一个 Bitcask 实例。支持的选项包括 read_write 或者 sync_on_put:
DirectoryName 对应目录的读写权限,同时一个时刻只能有一个进程以 read_write 的方式打开 Bitcask 实例。 |
| bitcask:open(DirectoryName) -> BitCaskHandle | {error, any()} | 在指定目录下以只读模式打开或新建一个 Bitcask 实例。连接的进程需要有 DirectoryName 对应目录及其内部所有文件的读权限。 |
| bitcask:get(BitCaskHandle, Key) -> not_found | {ok, Value} | 获取指定键对应的值。 |
| bitcask:put(BitCaskHandle, Key, Value) -> ok | {error, any()} | 插入一个键值对。 |
| bitcask:delete(BitCaskHandle, Key) -> ok | {error, any()} | 删除指定键。 |
| bitcask:list_keys(BitCaskHandle) -> [Key] | {error, any()} | 返回所有的键。 |
| bitcask:fold(BitCaskHandle, Fun, Acc0) -> Acc | 对每一个键值对应用 Fun 函数,Fun 的函数签名为 F(K, V, Acc0) -> Acc。类似于 JavaScript 的 reduce。 |
| bitcask:merge(DirectoryName) -> ok | {error, any()} | 合并目录下的数据文件以减少重复的键值对。同时生成 hintfile 辅助加速程序启动时间。 |
| bitcask:sync(BitCaskHandle) -> ok | 强制刷盘。 |
| bitcask:close(BitCaskHandle) -> ok | 关闭 Bitcask 实例的连接并刷盘。 |
存储
文件组织
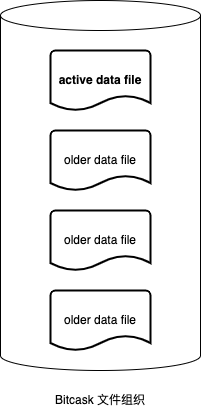
Bitcask 的文件组织非常简单,任意时刻目录下最多只有一个 active data file 接收写操作,其余都是不可修改的历史数据文件。任意时刻 Bitcask 只允许一个进程以写模式建立连接,写入进程只会向 active data file 写入,当其大小超过指定阈值后就会关闭当前文件,然后新建一个 active data file。
数据格式
写入进程以追加写的方式写入 active data file,从而避免了随机写的磁盘寻址,其写入数据格式如下:
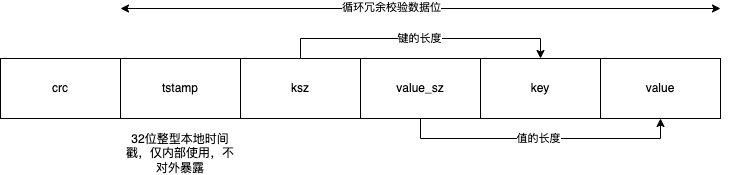
crc:循环冗余校验码,验证数据完整性tstamp:32位整型本地时间戳,仅内部使用,不对外暴露ksz:键的长度value_sz:值的长度key:键的内容value:值的内容
对于每一条记录,前面四个部分都是定长,以此为基址 base,则 base 到 base + ksz 就是键的内容,base + ksz 到 base + ksz + value_sz 就是值的内容。
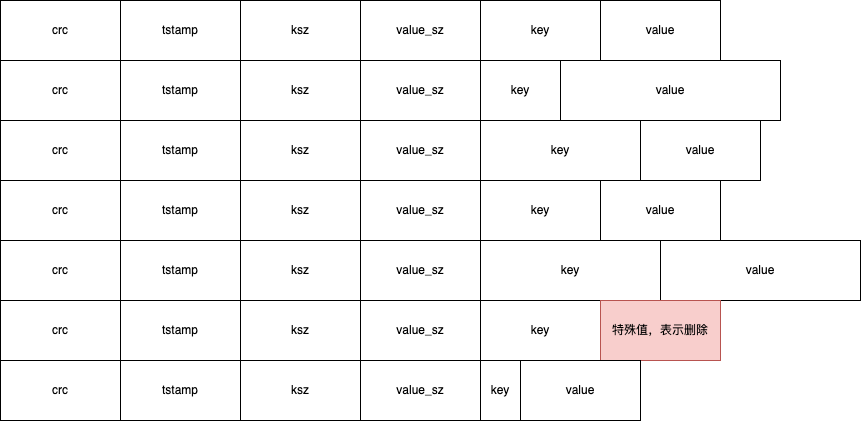
如果要删除指定的键,Bitcask 会再次追加写入一个键值对,只不过写入的值是一个特殊值,程序后续读到这条记录时比较值的内容就可以判断该条记录是否已被删除。所以,Bitcask 每个文件内容就是一行行的记录:
读写
写
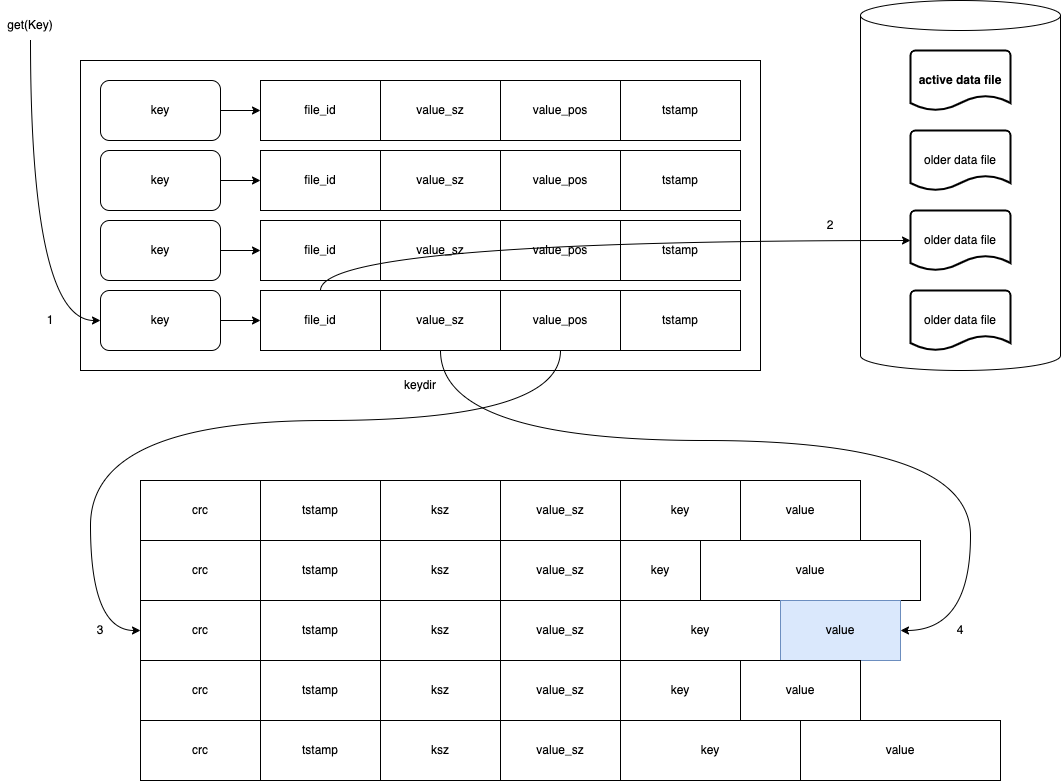
Bitcask 写入的同时会在内存中维护写入的键到数据文件的映射(keydir):
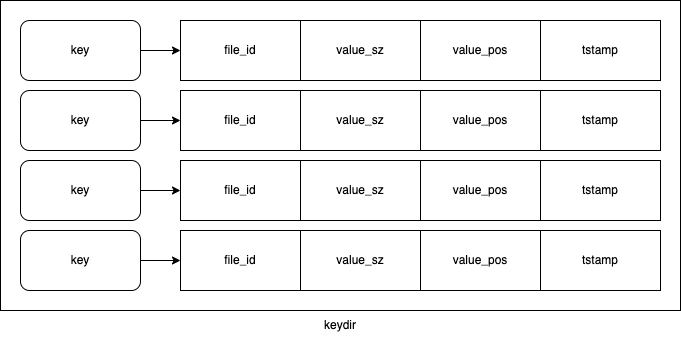
其中 file_id 能够定位具体的数据文件,value_pos 是该条记录的值在文件中的起始偏移位置,那么 value_pos 到 value_pos + value_sz 就是值的内容。因为 Bitcask 每次写数据的长度是可知的,值在每条记录中的偏移量可知,写之前 active data file 文件总长也可知,所以 value_pos 也能够推算出来。
对于重复写入的键值对,磁盘上会存在同一个键的多条记录,但是 keydir 中始终只保留最新的映射。
读
读取时先根据键查询 keydir 得到数据文件的映射,然后根据 file_id 定位数据文件,最后根据 value_pos 和 value_sz 返回值的内容,整个读取只涉及一次磁盘寻址。另一方面,文件系统的 read-ahead 缓存会进一步减少磁盘的交互:
数据合并
由于 Bitcask 追加写的特性,有两种类型的数据是冗余的:
- 被标记删除的数据
- 同一个键的旧版本的数据
所以,为了避免磁盘空间的浪费,需要额外的数据合并操作对磁盘上的数据瘦身。数据合并只处理只读的数据文件,遍历剔除掉已删除和旧版本的数据。另外,每一个合并后的数据文件同时额外有一个对应的 hint file:
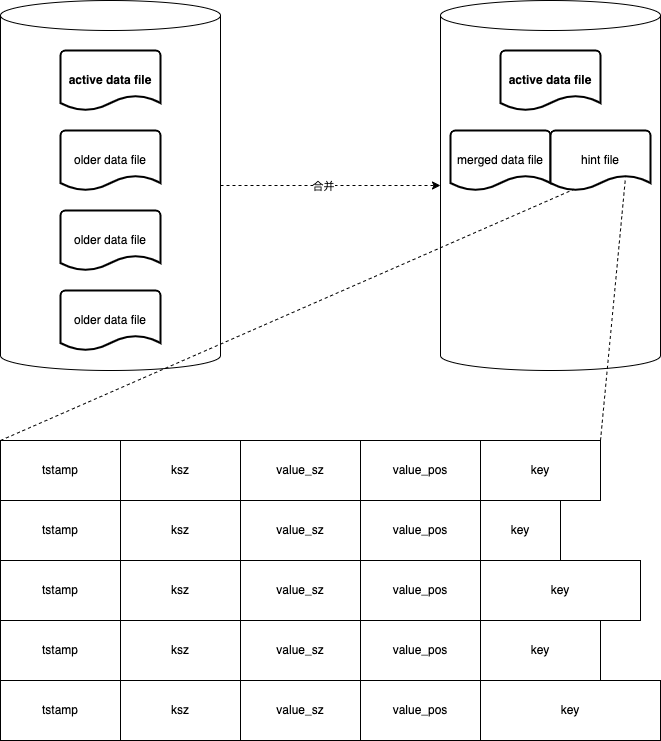
hint file 也是行记录的文件,每一行存储了:
tstamp:时间戳ksz:键的长度value_sz:值的长度value_pos:值在数据文件中的起始地址偏移量key:键
当程序启动时,如果 hint file 存在,那么就可以直接扫描 hint file 构建 keydir 从而加速程序启动;反之,则要扫描数据文件。
性能数据
原文并没有给出非常正规的测试报告,仅列出了一些早期未优化的测试数据:
- 读写延迟:毫秒内
- 写吞吐:5000~6000次/秒
- 内存占用:几百万的键在
1GB内(keydir需要)
总结
Bitcask 的整体设计思路非常简单,其设计目的也不是为了成为最快的 KV 存储,而是最适合 Riak 的存储引擎,在足够快的同时有着高质量、简洁的代码,设计和数据格式。