【读】The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing
介绍
面对日益增长的大规模无界、无序数据的处理需求,当前的技术手段存在诸多不足:
- 以
MapRecue为代表的批处理系统无法满足数据处理的及时性要求,因为需要先收集所有的数据,然后再处理 - 很多流式系统对于大规模处理下的容错性缺少明确的保证
- 能够提供大规模处理和容错性的系统又缺少表达性和正确性
- 很多系统也缺少
exactly-once语义保证,从而影响正确性 - 缺少对窗口(
windowing)计算的支持或支持有限 - 某些支持基于事件时间(
event-time)的窗口计算的系统要么要求事件必须有序,要么窗口触发语义不够丰富 - 缺少高层次的编程模型能够直观的支持基于事件时间的会话(
session) - 虽然
Lambda架构能够解决大部分的问题,但是需要同时构建和维护两套系统,增加了成本
当前已有系统的主要问题在于认为数据是有界的,这个假设对当下海量且无序的数据处理的需求是不成立的;另外,需要一个简单但又强大的工具在满足上述场景的同时,又能在正确性,延迟和成本之间取得平衡;最后,需要转变由执行引擎决定系统语义的思想,不管是批处理,微批处理,还是流式处理,只要经过了合理的设计和实现,都能提供同等水平的正确性保证,而这三种执行引擎如今都广泛用于处理无界的数据。因此,在正确性保证的前提下,选择不同的执行引擎的决定因素就在于延迟和资源成本。
本文提出了一个统一的数据处理模型:
- 对无界,无序的数据,能够根据事件本身的维度特征进行窗口聚合,并按照事件时间排序计算,并且在正确性,延迟,和成本之间灵活调优
- 将
pipeline的实现拆解为四个维度,以提供清晰性,可组合性和灵活性:What:计算的结果是什么Where:参与计算的事件时间When:数据处理时间How:先前的计算结果如何与后续优化关联
- 将数据处理的逻辑概念与底层物理实现剥离,对于批处理,微批处理,和流式处理的选择,取决于用户对正确性,延迟,和成本的考量
具体来说,本文的主要贡献在于提出了:
- 窗口模型:支持非对齐的事件时间窗口,并提供简单的
API用于创建和使用窗口 - 触发模型:将数据处理结果的输出时机与
pipeline的运行时特征相绑定,并提供了强大和灵活的声明式API来描述触发的语义 - 增量式的处理模型:集成窗口模型和触发模型,支持计算的撤销和更新
- 可扩展的实现:既支持流式处理引擎(
MillWheel),也支持批处理引擎(FlumeJava),以及对Google Cloud Dataflow的外部二次实现,并提供了运行时无关的开源SDK - 一系列指导本文描述的模型设计的核心准则
Google产线环境下大规模无界,无序数据处理的真实案例探讨,正是这些真实需求驱动了本文描述的模型的开发
无界/有界与流式/批
相比于流式/批,本文倾向于使用无界/有界来描述无限/有限的数据集,因为前者可能暗示使用了特定的执行引擎。实际上,无界的数据同样可以用连续运行的批处理引擎处理,而设计合理的流式处理引擎同样可以处理有界的数据。
窗口
窗口将一个数据集划分为有限个数的组。在处理无界数据时,窗口对于某些操作是必须的(如聚合,外连接,以时间为界的操作),而对于其他操作(如过滤,映射,内连接)则不是必须的。对于有界数据来说,窗口是可选的,不过依然在很多场景下适用(如对已经处理过的无界数据的一部分进行大批量的更新,即 backfill)。窗口始终是基于时间的,虽然某些系统支持基于元组的窗口,不过这依然是基于时间的窗口,其中有序的元素隐含着对应递增的逻辑时间。窗口分为对齐和非对齐,前者窗口的边界与特定的时间间隔同步,后者不同的窗口可以在不同的时间开始和结束。
固定窗口
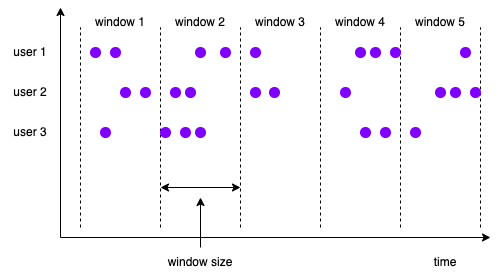
也称为滚动窗口(tumbling window),每个窗口都是固定的大小,且彼此之间没有重叠,通常都是对齐的,例如,每小时生成大小为1小时的窗口:
- 窗口1:[12:00, 13:00)
- 窗口2:[13:00, 14:00)
- 窗口3:[14:00, 15:00)
- …
不过,有时候为了保证窗口对齐,会将窗口按照键以某个随机值进行偏移。
滑动窗口
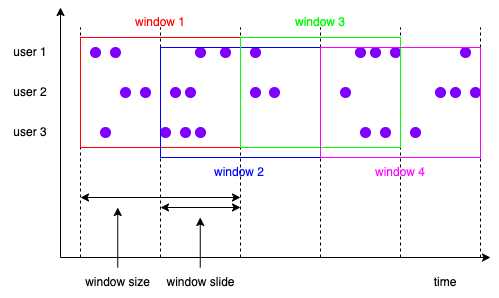
滑动窗口由窗口大小和滑动周期构成,例如,每分钟生成大小为1小时的窗口:
- 窗口1:[12:00, 13:00)
- 窗口2:[12:01, 13:01)
- 窗口3:[12:02, 13:02)
- …
滑动周期可能会小于窗口大小,所以相邻两个窗口之间有重叠,当滑动周期等于窗口大小的时候,滑动窗口就退化成了滚动窗口。滑动窗口一般也是对齐的。
会话窗口
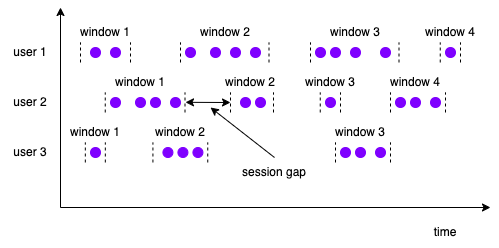
会话窗口用于框住某段时间内产生的数据子集,其大小一般以超时时间来衡量,在该超时时间内发生的事件都会归于该会话窗口。会话窗口一般是非对齐的。
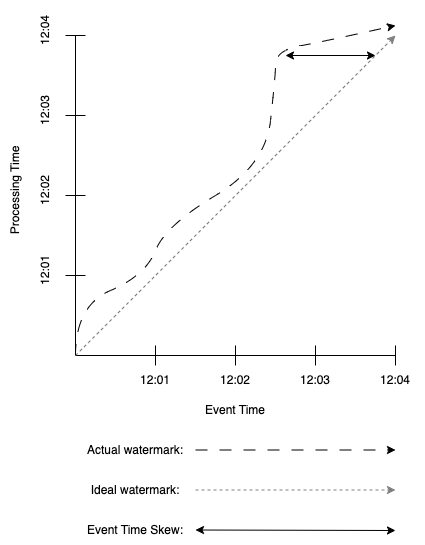
时间
数据处理中有两类时间:
- 事件时间:事件实际发生的时间
- 处理时间:事件被系统观测到并处理的时间
一般来说事件时间一旦生成后就不会改变,而处理时间则随着事件在系统中流动而不断变化。理想情况下,如果分别对事件时间和处理时间画一条线,那么这两条线是重合的。不过在实际中,由于通信延迟,调度算法,处理单个事件需要的耗时,以及 pipeline 的序列化等因素,事件时间与处理时间之间存在偏差(如下图所示)。本文使用类似于 MillWheel 的 watermark 来表示这种偏差,watermark 定义了事件时间的一个下界,表示所有事件时间小于 watermark 的事件都已经处理完毕。不过,这依然是个理想情况,为了容忍一定程度的事件到达系统的延迟,watermark 会滞后于最新的事件时间,而这个容忍时间又不可能无限长,所以实际中即使生成 watermark 后也依然有可能存在事件时间比 watermark 小的事件到达系统,这些事件称为 late event。
Dataflow 模型
核心原语
在批处理下,Dataflow SDK 提供了操作 (key, value) 键值对的两种方式:
ParDo:对每个输入,通过调用用户定义的方法(在Dataflow中称为DoFn),返回0个或者多个输出,各输入之间无关联,天然的适用于无界数据处理GroupByKey:将相同键的值聚合在一起,不过对于无界数据来说,何时将相同键聚合后的数据发给下游成为了一个问题,因为无法预知数据的边界,通用的解决方法是借助窗口
以下是一个 ParDo 的例子,对于每个输入,通过调用 ExpandPrefixes 方法,返回每个键的所有可能的前缀:
以下是一个 GroupByKey 的例子,将相同键的值聚合在一起:
窗口
支持按键聚合的系统一般会将 GroupByKey 以 GroupByKeyAndWindow 的形式实现,本文的首要贡献在于支持非对齐的窗口。具体来说:
Dataflow模型的视角下可以将所有窗口都当做非对齐的,并交由具体实现来为对齐式的窗口场景优化- 窗口计算可以拆解为两个操作:
Set<Window> AssignWindows(T datum):将输入分配给0个或者多个窗口Set<Window> MergeWindows(Set<Window> windows):聚合时将多个窗口合并为一个
为了支持基于事件时间的窗口,需要将数据传输的格式从 (key, value) 改为 (key, value, event_time, window),event_time 是事件时间,window 默认是一个全局窗口,覆盖所有的事件,同时也适配了有界数据的场景。
窗口分配
如果一个输入属于多个窗口,那么窗口分配会给每个窗口创建一个输入的副本。
在下面这个例子中,键值对 (k, v1) 和 (k, v2) 分别复制到了两个窗口中。窗口的分配也不需要等到聚合时,可以在 pipeline 的任意执行点发生:
窗口合并
窗口合并发生于 GroupByKeyAndWindow 操作,我们以超时时间为30分钟的会话窗口为例,假设有 (k1, v1),(k2, v2),(k1, v3),(k1, v4) 四个事件,其初始默认的窗口都为。然后,AssignWindows 根据每个事件到达的起始时间分配一个时长为30分钟的会话窗口,在这期间如果有相同键的事件到达,则也将其归到同一个窗口内。然后,GroupByKeyAndWindow 操作可以拆解为如下步骤:
DropTimestamps:丢弃事件的时间戳,因为这里只涉及窗口计算GroupByKey:按照键聚合(value, window)元组MergeWindows:合并每个键下(value, window)元组中的窗口,具体的合并逻辑由窗口策略决定。在上述的例子中,如果两个(value, window)元组中的窗口存在重叠,则每个元组合并后的窗口为两个窗口的并集GroupAlsoByWindow:对每个键下的(value, window)元组按照窗口聚合,在上述例子中,v1和v4因为有相同的窗口,所以被聚合在了一起ExpandToElements:将每个键下的(value, window)元组展开为(key, value, event_time, window)的形式,新的event_time在上述例子中采用的是窗口的结束时间,不过实际上只要是大于窗口内最早的事件的时间戳都行。
API
现在通过 Cloud Dataflow SDK 的代码示例来展示如何使用窗口。下述代码将数据按照键聚合后,求所有值的加和:
1 | PCollection<KV<String, Integer>> input = IO.read(...); |
如果要支持超时时间为30分钟的会话窗口,则在求和前调用 Window.into 即可:
1 | PCollection<KV<String, Integer>> input = IO.read(...); |
触发器和增量处理
目前为止,还遗留两个问题:
- 需要支持基于元组和处理时间的窗口,不然会和当前已有的系统不兼容
- 需要知道窗口中的数据计算结果何时可以下发到下游
本文认为借助 watermark 来解决第二个问题是不够的,因为 watermark 不能百分百确保所有数据都已经到达,真实场景中总会有晚到的数据。Lambda 架构则提供了一个思路:流式引擎部分提供低延迟的计算,不过其结果是近似值,而批处理引擎则提供最终一致性正确的结果。不过,如何将两者合并到一个 pipeline 中?
本文提出了触发器(trigger)的概念,和窗口的关系为:
- 窗口:根据事件时间决定如何对事件分组
- 触发器:决定何时(处理时间)告知窗口计算的数据结果可以下发到下游
Google 实现的系统内置了几类触发器的实现用于在多种场合触发:
- 当所有的数据已被系统接收时(预估,非精确,如
watermark) - 处理时间线上的某个时间点
- 响应数据到达(如数量,大小,
data punctuations,模式匹配等满足了一定的条件)
另外,不同的触发器之间还可以进行逻辑组合,例如使用 and,or,循环,序列等等。
引入触发器后,同一个窗口的计算结果就有可能被多次下发,系统也提供了三种处理模式:
- 丢弃(
Discarding):一旦窗口被触发,其内容下发后即被丢弃,后续触发和之前的触发没有任何关系。如果多次窗口触发的结果是幂等的,则可以采用该模式 - 累加(
Accumulating):窗口被触发后,其计算结果会持久化,后续触发结果会作为历史结果的修正。适合于数据消费方收到新的窗口数据,直接替换旧数据的场景。例如某个窗口计算是求窗口中所有数据的最大值,第一次触发时下发目前的最大值,后续有数据再次到达时根据持久化的历史值,直接和当前值比较就可以得到最新的最大值 - 累加和撤销(
Accumulating and Retracting):在Accumulating的基础上,触发的窗口计算结果同样会先持久化,如果后续有新的触发,则会下发两个值,一个是用于告知下游系统撤销上次的值,另一个是最新的窗口计算结果。不过,这也需要下游系统具有响应数据撤销事件的能力
实现和设计
设计原则
Dataflow 模型的一些设计原则:
- 永远不要依赖任何完整性的概念
- 要有足够好的灵活性,既可以适应已知的各种使用场景,又能支持未来可能的扩展
- 在预想的执行引擎中要添加有价值的东西,而不仅仅是因为合理
- 鼓励清晰的实现
- 支持在数据产生的上下文中进行强大的数据分析