-- Logs begin at Sun 2021-12-26 04:48:21 UTC, end at Sun 2023-03-12 06:34:53 UTC. -- Mar 12 05:08:43 example-name systemd[1]: Started Monitoring system and forwarder. Mar 12 05:38:45 example-name grafana-agent[1049084]: ts=2023-03-12T05:38:45.6366501Z caller=cleaner.go:203 level=warn agent=prometheus component=cleaner msg="unable to fi> Mar 12 06:08:45 example-name grafana-agent[1049084]: ts=2023-03-12T06:08:45.63549564Z caller=cleaner.go:203 level=warn agent=prometheus component=cleaner msg="unable to f> Mar 12 06:20:16 example-name systemd[1]: Stopping Monitoring system and forwarder... Mar 12 06:20:16 example-name systemd[1]: grafana-agent.service: Succeeded. Mar 12 06:20:16 example-name systemd[1]: Stopped Monitoring system and forwarder. Mar 12 06:20:16 example-name systemd[1]: Started Monitoring system and forwarder.
# Sample config for Grafana Agent # For a full configuration reference, see: https://grafana.com/docs/agent/latest/configuration/. server: log_level: warn
metrics: global: scrape_interval: 1m wal_directory: '/var/lib/grafana-agent' configs: # Example Prometheus scrape configuration to scrape the agent itself for metrics. # This is not needed if the agent integration is enabled. # - name: agent # host_filter: false # scrape_configs: # - job_name: agent # static_configs: # - targets: ['127.0.0.1:9090']
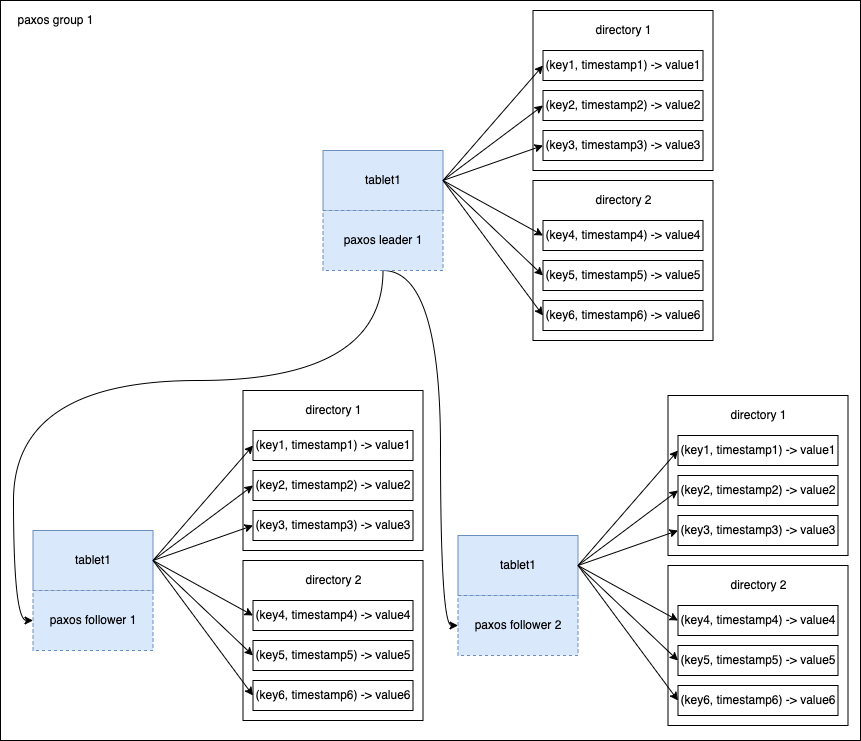
为什么这里资源的名称字段要定义为 name 而不是 id?首先从命名上来说 name 本身要比 id 更适合作为 名称 一词的命名。其次,name 也是一个较为宽泛的词语,例如文件资源的 name 代表的是文件的名称还是完整的路径?通过将 name 作为标准字段,使得开发人员必须要选择更适合的命名,例如 display_name,title 或者 full_name。
为什么不直接使用资源 ID 来定位资源?一个系统中往往有多个资源,单纯的资源 ID 不具有辨识度以及缺少上下文信息。例如,如果使用数据库表的自增主键作为资源 ID,则无法简单的通过数字来定位资源。如果想要通过资源 ID 来定位资源,则势必要扩展资源 ID 的定义,例如使用元组来表示资源 ID,如 (bucket, object) 用于定位某个对象存储服务的对象。不过,这也带来了几个问题:
对开发人员不友好,需要额外理解和记忆(例如不同资源 ID 的元组元素个数不同,每个元组元素代表的含义是什么)
解析元组比解析字符串更为困难
对基础设施组件不友好,例如日志和访问控制系统无法直接理解元组
限制了 API 设计的灵活性,如提供可复用的 API 接口
标准方法
标准方法的作用在于为大多数的服务场景提供统一、易用的接口,超过 70% 的 Google APIs 都是标准方法。Google APIs 设计了5种标准方法:
在面向资源的 API 设计下,资源的模式由 API 决定。为了让客户端能够给资源添加自定义的元数据(例如标记某台虚拟机为数据库服务器),资源定义中应当添加一个 map<string, string> labels 字段,例如:
1 2 3 4
message Book { string name = 1; map<string, string> labels = 2; }
长时间运行操作
如果某个 API 方法需要很长时间才能完成,则该方法应该设计成返回一个长时间运行操作资源给客户端,客户端可以通过这个资源来跟踪方法的执行进展及获取执行结果。Operation 定义了标准的接口来处理长时间运行操作,各 API 不允许自行定义额外的长时间运行操作接口以避免不一致。
长时间运行操作资源必须以响应消息体的方式返回给客户端,并且该操作的任何直接结果都应该反应到其他 API 中。例如,如果有一个长时间运行操作用于创建资源,即使该资源未创建完成,LIST 和 GET 标准方法也应该返回该资源,只是该资源会被标记为暂未就绪。当长时间操作完成时,Operation.response 字段应当包含该操作的执行结果。
在某些场景下,需要为特定的数据格式定义简单的语法,例如允许接受的文本输入。为了在各 API 间提供一致的开发体验,API 设计者必须使用如下的 Extended Backus-Naur Form (EBNF) 的变种来定义语法:
1 2 3 4 5 6 7
Production = name "=" [ Expression ] ";" ; Expression = Alternative { "|" Alternative } ; Alternative = Term { Term } ; Term = name | TOKEN | Group | Option | Repetition ; Group = "(" Expression ")" ; Option = "[" Expression "]" ; Repetition = "{" Expression "}" ;
整数类型
设计 API 时应当避免使用无符号整型例如 uint32 和 fixed32,因为某些重要的编程语言或者系统不能很好的支持无符号整型,例如 Java,JavaScript 和 OpenAPI,并且它们很大可能会造成整型溢出错误。另一个问题是不同的 API 可能将同一个值各自解析为不同的无符号整型或者带符号整型。
在某些场景下类型为带符号整型的字段值如果是负数则没有意义,例如大小,超时时间等等;API 设计者可能会用-1(并且只有-1)来表示特殊的含义,例如文件结束符(EOF),无限的超时时间,无限的配额或者未知的年龄等等。这种用法必须明确的在接口文档中标注以避免迷惑。同时 API 设计者也应当标注当整型数值为0时的系统行为,如果它不是非常直白明了的话。
局部响应
在某些情况下,客户端可能只希望获取资源的部分属性。Google API 通过 FieldMask 来支持这一场景。
对于任意 Google API 的 REST 接口,客户端都可以传入额外的 $fields 参数来表明需要获取哪些字段:
1 2
GET https://library.googleapis.com/v1/shelves?$fields=shelves.name GET https://library.googleapis.com/v1/shelves/123?$fields=name
网络 API 依赖分层的网络架构来传输数据,大多数的网络协议层对输入和输出的数据量设置了上限,一般而言,32 MB 是大多数系统中常用的大小上限。
如果某个 API 涉及的传输载荷超过 10 MB,则需要选择合适的策略以确保易用性和未来的扩展的需求。对于 Google APIs 来说,建议使用流式传输或者媒体上传/下载的方式来处理大型载荷,在流式传输下,服务端能够以增量同步的方式处理大量数据,例如 Cloud Spanner API。在媒体传输下,大量的数据流先流入到大型的存储系统中,例如 Google Cloud Storage,然后服务端可以异步的从存储系统中读取数据并处理,例如 Google Drive API。
在实践中开发人员难以正确的处理可选字段,大多数的 JSON HTTP 客户端类库,包括 Google API Client Libraries,无法正确区分 proto3 的 int32,google.protobuf.Int32Value 以及 optional int32。如果存在一个方案更清晰而且也不需要可选的基本类型字段,则优先选择该方案。如果不使用可选的基本类型字段会造成复杂度上升或者含义不清晰,则选择可选的基本类型字段。但是不允许可选字段搭配包装类型使用。一般而言,从简洁和一致性考虑,API 设计者应当尽量选择基本类型字段,例如 int32。
版本控制
Google APIs 借助版本控制来解决后向兼容问题。
所有的 Google API 接口都必须包含一个主版本号,这个主版本号会附加在 protobuf 包的最后,以及包含在 REST APIs 的 URI 的第一个部分中。如果 API 要引入一个与当前版本不兼容的变更,例如删除或者重命名某个字段,则必须增加主版本号,从而避免引用了当前版本的用户代码受到影响。
所有 API 的新主版本不允许依赖同 API 的前一个主版本。一个 API 本身可能会依赖其他 API,这要求调用方知晓被依赖的 API 的版本稳定性风险。在这种情况下,一个稳定版本的 API 必须只依赖同样是稳定版本的其他 API。
同一个 API 的不同版本在同一个客户端应用内必须能在一段合理的过渡时期内同时生效。这个过渡时期保障了客户端应用升级到新的 API 版本的平滑过渡。同样的,老版本的 API 也必须在废弃并最终停用之前留有足够的过渡时间。
Posted onWord count in article: 2.4kReading time ≈4 mins.
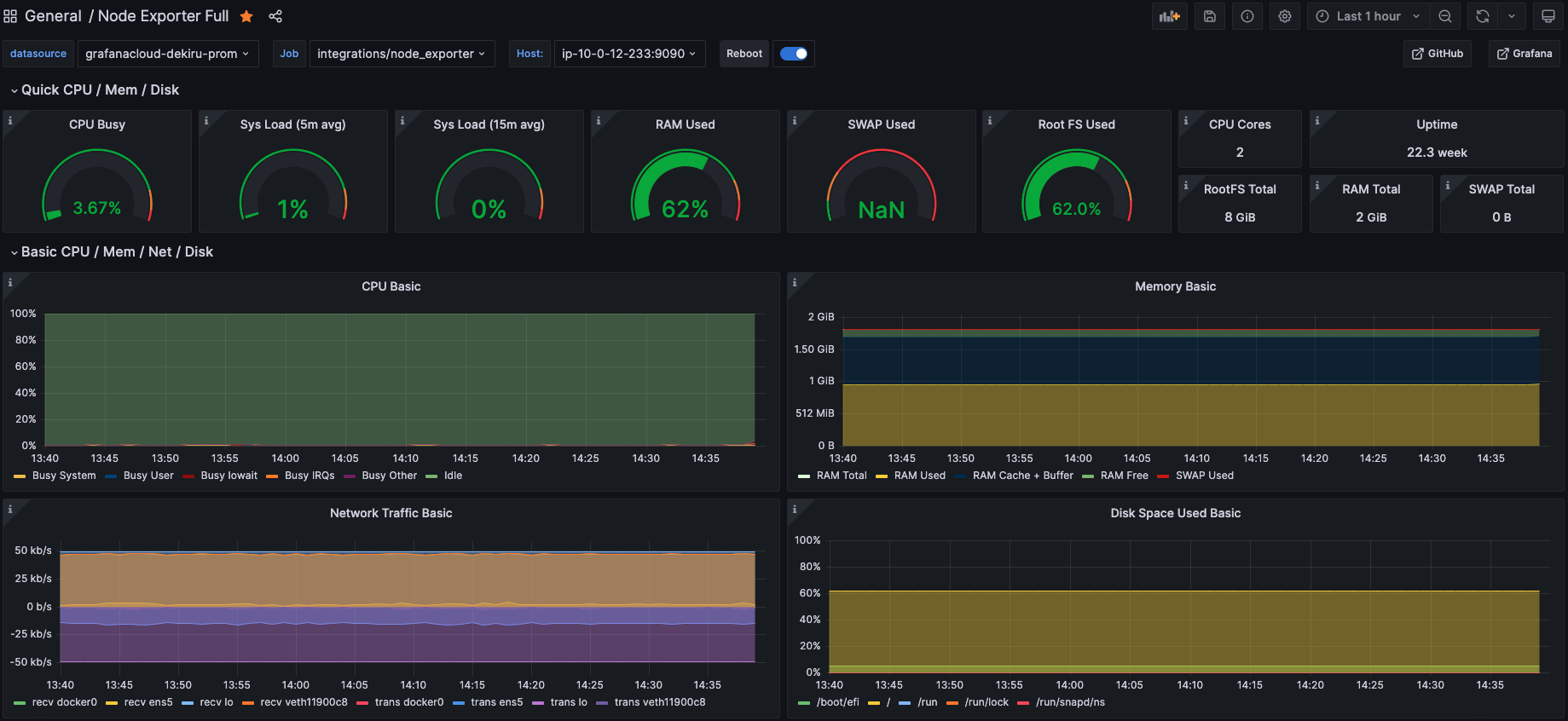
AWSEC2 的监控页面默认没有显示内存使用率,需要搭配 CloudWatch 配置使用。
由于需要在 EC2 上安装 CloudWatch agent 来上报监控数据到 CloudWatch,所以需要先为 EC2 配置 IAM 角色来授予需要的权限。创建 IAM 角色时,在第一步的 Trusted entity type 选择 AWS service,Use case 选择 EC2;在第二步的 Permissions policies 添加 CloudWatchAgentServerPolicy 即可。更多细节可参考 Create IAM roles and users for use with CloudWatch agent。
2022-10-09T13:27:36Z E! WriteToCloudWatch failure, err: NoCredentialProviders: no valid providers in chain caused by: EnvAccessKeyNotFound: failed to find credentials in the environment. SharedCredsLoad: failed to load profile, . EC2RoleRequestError: no EC2 instance role found caused by: EC2MetadataError: failed to make EC2Metadata request
创建 EKS 集群时需要绑定一个 IAM 角色,因为 Kubernetes 的 control plane 需要管理集群内的资源,所以需要有相应的操作权限。
首先进入 IAM 控制台,选择左侧 Access management 下的 Roles,点击 Create role。在 Trusted entity type 下选择 AWS service,然后在 Use cases for other AWS services 下选择 EKS,接着选择 EKS - Cluster 并点击 Next。在 Add permissions 这步直接点击 Next。在最后一步设置所创建的角色的名字,如 eksClusterRole,最后点击 Create role 创建角色。
创建集群
我们通过 AWS 管理后台中的 Amazon Elastic Kubernetes Service 界面来创建集群,第一步的 Configure cluster 主要设置集群的名称,如 my-cluster,以及绑定在之前步骤中所创建的 Cluster service role。第二步的 Specify networking 这里基本都保持默认,只是将 Cluster endpoint access 设置为 Public and private。第三步的 Configure logging 可以暂时不开启日志监控。最后在第四步的 Review and create 点击 Create 创建集群。
创建 Node group
当集群的状态变为 Active 后就表示集群创建成功,不过此时集群中还没有任何 Node,所以系统级别的 Pod 还无法正常工作,比如在集群详情的 Resources 下查看某个 coredns 的 Pod 会显示 FailedScheduling,因为 no nodes available to schedule pods。
我们需要创建 Node group 来为系统添加可用的 Node。
创建 Node IAM role
在创建 Node group 前,需要创建一个 Node IAM role。因为集群中的 Node 内部会运行着一个叫做 kubelet 的程序,它负责和集群的 control plane 进行通信,例如将当前 Node 注册到集群中,而某些操作需要调用 AWS 的接口,所以和 Cluster service role 类似,也需要绑定相应的权限。
这里同样也是通过 IAM 控制台 来创建角色,在 Trusted entity type 下选择 AWS service,在 Use case 下选择 EC2,然后点击 Next。在第二步的 Add permissions 需要添加 AmazonEKSWorkerNodePolicy,AmazonEC2ContainerRegistryReadOnly 和 AmazonEKS_CNI_Policy 三个权限,虽然文档中说不建议将 AmazonEKS_CNI_Policy 权限添加到 Node IAM role 上,不过这里作为示例教程将三个权限都绑定在了 Node IAM role 上。最后也是点击 Create role 创建角色。
创建 Node group
在集群详情的 Compute 下点击 Add node group 来创建 Node group,在第一步 Configure node group 中设置 node group 的名称及绑定在之前步骤中所创建的 Node IAM role。在第二步 Set compute and scaling configuration 里配置节点的类型和数量等信息,作为教程都采用默认配置。第三步 Specify networking 同样采用默认配置。最后在第四步的 Review and create 点击 Create 完成创建。
最后当所创建的 Node group 的状态变为 Active 以及该 Node group 下的 Node 的状态变为 Ready 时说明节点创建成功。此时再查看集群详情下 Resources 的 coredns 的 Pod 已成功分配了 Node 运行。
连接 EKS 集群
日常需要通过 kubectl 管理集群,所以需要先在本地配置访问 EKS 集群的权限。kubectl 本质上是和 Kubernetes API server 打交道,而创建集群时 Cluster endpoint access 部分选择的是 Public and private,所以在这个场景下能够从公网管理 EKS 集群。
首先需要安装 AWS CLI 和 kubectl。然后在本地通过 aws configure 来设置 AWS Access Key ID 和 AWS Secret Access Key。根据 Enabling IAM user and role access to your cluster 的描述,创建集群的账户会自动授予集群的 system:masters 权限,本文是通过 AWS 的管理后台创建集群,当前登录的账户为 root,所以 aws configure 需要设置为 root 的 AWS Access Key ID 和 AWS Secret Access Key:
When you create an Amazon EKS cluster, the AWS Identity and Access Management (IAM) entity user or role, such as a federated user that creates the cluster, is automatically granted system:masters permissions in the cluster’s role-based access control (RBAC) configuration in the Amazon EKS control plane.
一般公司生产环境中的 AWS 是不会直接使用 root 账户登录的,而是创建 IAM 用户,由于这里是个人的 AWS 账户所以直接使用了 root,反之就需要使用 IAM 用户的 AWS Access Key ID 和 AWS Secret Access Key。设置完成之后可以通过 aws sts get-caller-identity 来验证当前用户是否设置正确:
# Please edit the object below. Lines beginning with a '#' will be ignored, # and an empty file will abort the edit. If an error occurs while saving this file will be # reopened with the relevant failures. # apiVersion: v1 data: mapRoles: | - groups: - system:bootstrappers - system:nodes rolearn: arn:aws:iam::123:role/AmazonEKSNodeRole username: system:node:{{EC2PrivateDNSName}} mapUsers: | - groups: - system:masters userarn: arn:aws:iam::123:user/eks username: eks kind: ConfigMap metadata: creationTimestamp: "2022-09-11T06:33:38Z" name: aws-auth namespace: kube-system resourceVersion: "33231" uid: 6b186686-548c-4c99-9f65-0381da1366a4
这里在 data 下新增了 mapUsers,授予用户 ekssystem:masters 的角色:
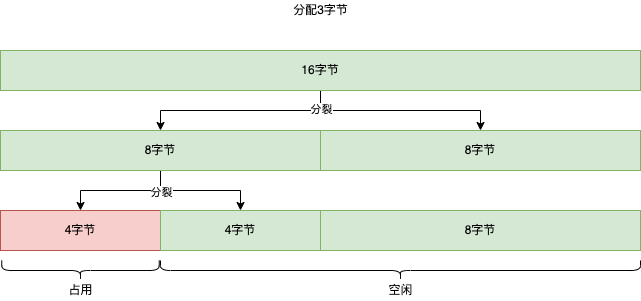
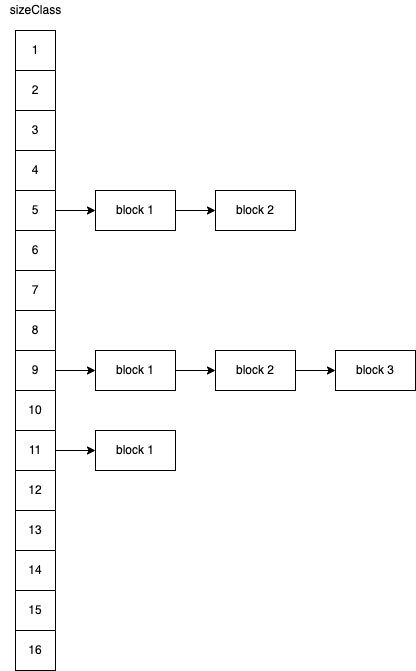
// 初始化空闲列表 for (inti=0; i < MAX_SIZE_CLASS; i++) { intsizeClass= i + 1; intheadSentinelAddress= Constant.HEAD_SENTINEL_SIZE * i; this.blockLists[i] = newBlockList(headSentinelAddress, this.memory, sizeClass); this.blockLists[i].clear(); }
// The single full block Blockblock=newBlock(allHeadSentinelSize, this.memory); block.setSizeClass(MAX_SIZE_CLASS); block.setFree(); this.blockLists[MAX_SIZE_CLASS - 1].insertFront(block); } }
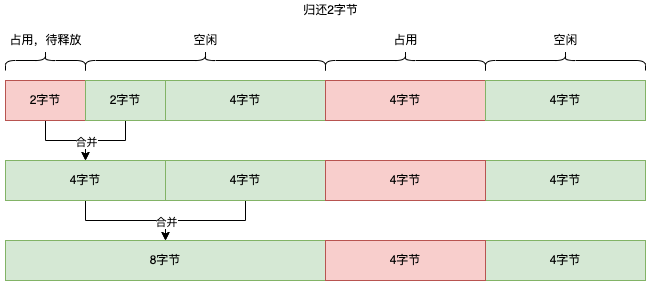
原作者在这里巧妙的在不引入额外的元数据的情况下解决了这个问题。首先,对于某个 sizeClass 为 k 的内存块来说,它的起始地址一定是C2k,其中 C 为整数。这里使用数学归纳法来证明,假设系统内存最多支持2N个字节,则初始状态下整个系统只有一个内存块,k 就等于 N,该内存块的起始地址为0,满足C2k,取 C = 0 即可。假设某个 sizeClass 为 k 的内存块的起始地址满足C2k,则需要进一步证明分裂后的两个内存块的起始地址为C′2k−1。而分裂后的内存块的起始地址分别为C2k和C2k+2k−1,又C2k=(2C)2k−1,C2k+2k−1=(2C+1)2k−1,证明完毕。同时,由这些公式可以发现,对于左兄弟内存块来说,C 是偶数,而对于右兄弟内存块来说 C 是奇数。更进一步来说,左右兄弟内存块的地址差异仅在于从低位往高位数的第 k + 1 位不同。
因此,根据某个内存块的地址推算出兄弟内存块的地址只需要将当前内存块的地址从低位往高位数第 k + 1 位反转即可。这种涉及反转比特位的操作就可以使用异或运算,我们可以将内存块的地址和 1 << sizeClass(也就是2k)进行异或运算,得到的地址就是对应兄弟内存块的地址。
var context = new Dictionary<string, object>() { { "numbers", new[] { 1, 2, 3 } }, }; string text = @"<ol>{% for number in numbers %}<li>{{ number }}</li>{% endfor %}</ol>"; Template template = new Template(text, context); string result = template.Render();
这里将 text 传入 Template 的构造函数后,会在构造函数中完成模板解析,后续的 Render 调用都不需要再执行模板解析。
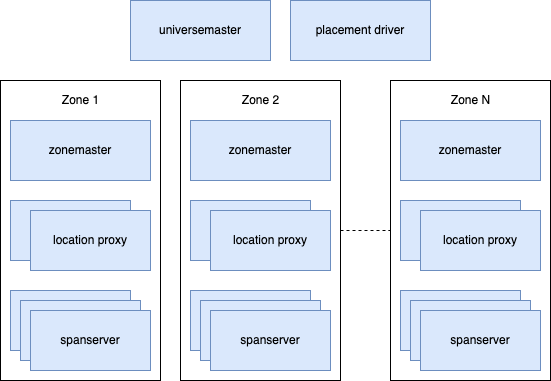
一个 Spanner 实例以一组 zone 的形式来组织,每个 zone 差不多等同于部署了一批 Bigtable 服务器。每个 zone 是一个可管理的部署单元。系统在各个 zone 之间进行数据复制。当上线或者下线数据中心时,可以向运行中的系统添加或者删除 zone。zone 也是物理隔离的单位:一个数据中心内可能有1个或者多个 zone,例如不同应用程序的数据需要分片到同一个数据中心内的不同服务器上。
上图展示了 Spanner 的一个 universe 中各服务器的职责。每个 zone 有一个 zonemaster 和成百上千台 spanserver。zonemaster 向 spanserver 分发数据,spanserver 向客户端提供数据服务。同时,客户端通过每个 zone 内的 location proxy 来确定需要访问哪台 spanserver 获取数据。universe master 和 placement driver 目前是单点的。universe master 主要是一个控制台,用于展示所有 zone 的状态信息,从而方便调试。placement driver 负责自动的在各个 zone 之前进行数据迁移,这个的操作耗时一般是分钟级。出于满足数据副本数量的要求以及实现数据访问的负载均衡,placement driver 会周期性的和 spanserver 通信从而确认哪些数据需要迁移。出于篇幅考虑,论文只会描述 spanserver 的实现细节。
TrueTime 的实现由每个数据中心中的一组 time master 机器完成,每个机器上存在一个 timeslave 守护进程。大多数的 time master 安装了具有专用天线的 GPS 接收器;这些机器在物理上相互隔离,从而降低天线异常,电磁波干扰和电子欺骗的影响。剩下的 time master(被称之为 Armageddon masters)则配有原子钟。一个原子钟并不是太昂贵;一个 Armageddon master 的成本和一个 GPS master 的成本相当。各个 time master 会定期的互相对比各自的参照时间。每个 time master 也会对比自己的参照时间和本地时钟,如果两者相差过大则该 time master 会退出集群。在时钟同步期间,Armageddon masters 会保守的根据最差情况的时钟漂移来逐渐增加时间的不确定性。GPS masters 的时间不确定性误差一般接近于0。
每个 timeslave 守护进程会拉取多个 time master 的参照时间来减少单个 time master 异常造成的时间误差。timeslave 轮询的 time master 一部分来自于就近数据中心的 GPS master;剩下的来自于更远的数据中心的 GPS master 以及一些 Armageddon master。获取到其他 time master 的参照时间后,timeslave 守护进程会通过一种 Marzullo 算法的变种来识别出不可信的值,然后根据可信的值同步本地时钟。为了避免异常的本地时钟造成影响,如果某个机器的时钟误差频繁超过组件规范和工作环境下的误差上限,则该机器会从集群中剔除。
在时钟同步期间,timeslave 守护进程也会逐渐增加时间的不确定性。记ϵ表示保守最差情况下的本地时钟偏移。ϵ的值同时也依赖 time master 的不确定性以及和 time master 的通信延迟。在 Google 的生产环境中,ϵ呈现出随时间变化的锯齿形函数,在每次轮询 time master 间隔间ϵ的值在1到7毫秒内浮动。因此在大多数时间里ϵˉ的值为4毫秒。当前 timeslave 守护进程轮询 time master 的时间间隔为30秒,以及时钟漂移速率为200微妙/秒,最后ϵ的浮动范围为0到6毫秒。而剩下的1毫秒则来源于和 time master 的通信延迟。当发生异常时,ϵ的偏移范围超过7毫秒也是有可能的。例如,有时候 time master 的不可用会造成数据中心范围内ϵ值的增加。类似的,服务器过载以及网络链路异常也有可能造成局部范围内ϵ的值产生毛刺。
并发控制
本节描述了 Spanner 如何使用 TrueTime 来保证并发控制下的正确性特性,以及如何利用这些正确性特性来实现诸如外部一致性事务,无锁只读事务以及非阻塞式的读取旧数据。例如要在某个时间戳 t 对整个数据库做一次审计读取操作,则借助这些特性可以保证这次操作一定能够读取到在时间戳 t 之前已经提交的事务修改。
Spanner 的模式变更事务基本上是标准事务的一个非阻塞式的变种。首先,它会被分配一个未来的时间戳,这个时间戳是在准备阶段生成的。因此,涉及几千台服务器的模式变更能够在尽可能少的影响到并发进行的事务的前提下完成。第二,依赖需要变更的模式的读写操作会和分配了时间戳 t 的模式变更事务保持同步:如果读写操作的时间戳小于 t,则这些操作可以继续进行;但是如果读写操作的时间戳大于 t,则需要阻塞等待模式变更事务完成。如果没有 TrueTiime,则定义模式修改发生在时间戳 t 就没有意义。
tsafePaxos的问题在于如果没有写操作,则这个值始终得不到更新。因此,如果某个期望读取时间戳 t 的快照读落在了某个最近一次写操作的时间戳小于 t 的 Paxos 组中,那么在没有新的写操作的情况下,这个快照读始终无法被执行。Spanner 通过主节点租约区间的不相交不变式(disjointness invariant)来解决这个问题。每个主节点维护了一个 Paxos 序号 n 到可能分配给下一个序号 n + 1 的最小时间戳的映射,即 MinNextTS(n)。当某个副本应用了序号 n 的指令后,则可以将tsafePaxos的值更新为 MinNextTS(n) - 1,因为下一个被分配的最小时间戳为 MinNextTS(n),减1就保证了不会超过这个值。